
Định nghĩa về Mô hình ngôn ngữ lớn (LLM)
Bạn sẽ làm quen với các mô hình ngôn ngữ và thế nào là mô hình ngôn ngữ lớn.

1. Tổng quan
Hãy tưởng tượng một cuộc trò chuyện với một người bạn, trong đó người bạn đó bắt đầu câu bằng: “Tôi định pha một cốc ________.” Con người có thể dự đoán rằng từ tiếp theo có thể là cà phê hoặc trà dựa trên kiến thức của họ về các lựa chọn đồ uống thông thường.

Tương tự, một mô hình ngôn ngữ được đào tạo để hiểu và dự đoán từ tiếp theo theo trình tự dựa trên ngữ cảnh của các từ trước đó. Nó học từ một lượng lớn dữ liệu văn bản và có thể đưa ra những dự đoán sáng suốt về từ nào có thể sẽ xuất hiện tiếp theo trong một ngữ cảnh nhất định.
Trước khi đi vào chi tiết hơn, trước tiên chúng ta hãy thảo luận về mô hình ngôn ngữ là gì.
2. Mô hình ngôn ngữ
Mô hình ngôn ngữ (Language Model, viết tắt là LM) có thể được định nghĩa là mô hình xác suất gán xác suất cho chuỗi từ hoặc mã thông báo trong một ngôn ngữ nhất định. Mục đích là nắm bắt cấu trúc và mô hình của ngôn ngữ để dự đoán khả năng xảy ra của một chuỗi từ cụ thể.

Giả sử chúng ta có vốn từ vựng V có chứa một chuỗi các từ (gọi là mã thông báo hay token) được ký hiệu là w1,w2,…wn. Ở đây N là độ dài của chuỗi. Mô hình ngôn ngữ ấn định xác suất (p) với mọi trình tự hoặc thứ tự có thể có của các từ thuộc bộ từ vựng (V) .
Ký hiệu xác suất của một chuỗi từ có thể được biểu thị như sau:
2.1. Ví dụ
Giả sử chúng ta có bộ từ vựng:
và chúng ta có các xác xuất giả định của các chuỗi từ có thứ tự xuất hiện trọng thực tế:

Từ kết quả xác xuất bên trên, ta có thể nhìn thấy rằng sự xuất hiện của chuỗi thứ tự the, cat, chase, the, mouse có xác xuất cao nhất.
Lưu ý: Các mô hình ngôn ngữ phải có kiến thức bên ngoài thì mới có thể gán các xác suất có ý nghĩa; do đó, chúng phải được đào tạo (hay còn gọi là huấn luyện, tiếng anh là training). Trong quá trình đào tạo này, mô hình học cách gán xác suất cao hơn cho các từ có nhiều khả năng tuân theo một ngữ cảnh nhất định. Sau khi đào tạo, mô hình ngôn ngữ có thể tạo văn bản bằng cách lấy mẫu các từ dựa trên các xác suất đã học này.
2.2. Sự dự đoán (Prediction)
Chúng ta cũng có thể dự đoán một từ theo một chuỗi. Một mô hình ngôn ngữ ước tính xác suất này bằng cách xem xét các xác suất có điều kiện (conditional probability) của mỗi từ dựa trên các từ trước đó trong chuỗi. Sử dụng quy tắc xác suất chuỗi (chain rule of probability), nên xác suất chung của chuỗi có thể được phân tách thành:
trong đó:
p(w1): là xác xuất xuất hiện của từ w1
p(w2|w1): là xác xuất của từ w2 khi theo sau w1
p(w3|w1,w2): là xác xuất xuất hiện của từ w3 theo sau chuỗi w1, w22.3. N-gram language model
Mô hình N-gram là một loại mô hình ngôn ngữ xác suất được sử dụng trong xử lý ngôn ngữ tự nhiên và ngôn ngữ học tính toán. Những mô hình này dựa trên ý tưởng rằng xác suất của một từ phụ thuộc vào n - 1 từ trước đó. Thuật ngữ “n-gram” dùng để chỉ một chuỗi liên tiếp các 𝑛 từ.
Ví dụ, hãy xem xét câu sau: Tôi thích ngắm hoa vàng.
Unigram (1-gram): “Tôi”, “thích”, “ngắm”, “hoa”, “vàng”.
Bigram (2-gram): “Tôi thích”, “thích ngắm”, “ngắm hoa”, “hoa vàng”.
Trigram (3-gram): “Tôi thích ngắm”, “thích ngắm hoa”, “ngắm hoa vàng”.
4-gram: “Tôi thích ngắm hoa”, “thích ngắm hoa vàng”.
5-gram: “Tôi thích ngắm hoa vàng”.
Các mô hình N-gram đơn giản và hiệu quả về mặt tính toán, khiến chúng phù hợp với nhiều tác vụ xử lý ngôn ngữ tự nhiên khác nhau. Tuy nhiên, những hạn chế của chúng bao gồm không có khả năng nắm bắt được sự phụ thuộc tầm xa trong ngôn ngữ (Footnote 1) và vấn đề thưa thớt khi xử lý các N-gram bậc cao hơn (Footnote 2)
Thuật toán của N-Gram như sau:
Mã thông báo (Tokenization): Chia văn bản đầu vào thành các từ hoặc mã thông báo riêng lẻ (gọi là token).
Tạo N-gram (N-gram generation): Tạo n-gram bằng cách hình thành các chuỗi N từ liên tiếp từ văn bản được mã hóa.
Đếm tần số (Frequency Counting): Đếm số lần xuất hiện của từng N-gram trong kho dữ liệu huấn luyện.
Ước tính xác suất (Probability estimation): Tính xác suất có điều kiện của mỗi từ dựa trên n-1 các từ cho trước bằng cách sử dụng đếm lượt xuất hiện.
Làm mịn (Smoothing) (tùy chọn): Áp dụng các kỹ thuật làm mịn để xử lý các n-gram không nhìn thấy (Footnote 1) và tránh xác suất bằng 0 (Footnote 2).
Tạo văn bản (Text generation): Bắt đầu với một bộ hạt giống ban đầu N-1 từ ban đầu, dự đoán từ tiếp theo dựa trên xác suất và lặp lại tạo ra các từ tiếp theo để tạo thành một chuỗi.
Lặp lại: Tiếp tục tạo từ cho đến khi đạt được độ dài mong muốn hoặc đạt đến điều kiện dừng.
Hãy xem một ví dụ thực tế:

Giải thích code:
Dòng 1: Import random mô-đun để tạo điều kiện cho các lựa chọn ngẫu nhiên trong quá trình tạo văn bản.
Dòng 3: Chúng ta tạo một class được đặt tên NGramLanguageModel
Dòng 4–7: Chúng ta khởi tạo một số biến cần thiết cho class, khởi tạo số N cho mô hình N-gram, dictionary ngrams và danh sách các mã thông báo giả để đệm cho chuỗi N token. Biến start_token dùng để cung cấp ngữ cảnh cho phần đầu của câu khi không có đủ từ đứng trước để tạo thành một N-gram hoàn chỉnh. Điều này đảm bảo việc tạo ra văn bản mạch lạc và nhất quán.
Dòng 9–17: Chúng ta xác định một phương thức được đặt tên train
N. Chúng tôi trích xuất N-gram hiện tại dưới dạng một bộ dữ liệu từ chuỗi mã thông báo và cập nhật số tần số của N-gram hiện tại trong biến dictionary ngrams.Dòng 19–34: Chúng ta xác định một phương thức được đặt tên generate_text để tạo văn bản dựa trên mô hình ngôn ngữ được đào tạo, bắt đầu bằng văn bản gốc.
Dòng 37–53: Chúng ta xác định kho ngữ liệu để đào tạo và kiểm tra mô hình ngôn ngữ. Sau đó, chúng ta tạo một thể hiện của class NGramLanguageModel với N = 2
3. Mô hình ngôn ngữ lớn
Các mô hình ngôn ngữ lớn (LLM) là các mô hình xử lý ngôn ngữ tự nhiên tiên tiến được đào tạo trên lượng lớn dữ liệu văn bản. Những mô hình này được thiết kế để hiểu và tạo ra văn bản giống con người dựa trên dữ liệu đầu vào mà chúng nhận được.
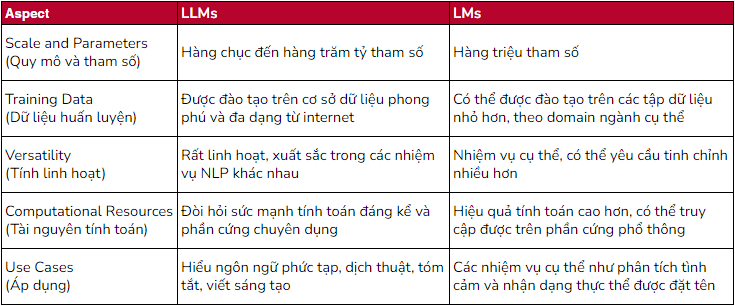
So sánh với các LM đơn giản hơn
LLM và LM đơn giản hơn khác nhau chủ yếu về quy mô, độ phức tạp và nhiệm vụ mà chúng được thiết kế để thực hiện. Dưới đây là so sánh giữa các mô hình ngôn ngữ lớn và các mô hình đơn giản hơn:
[Footnote]
Các mô hình N-gram tuy hữu ích trong việc hiểu và dự đoán các mẫu ngôn ngữ dựa trên các chuỗi từ ngắn nhưng lại gặp phải hai hạn chế chính:
Không có khả năng nắm bắt các phụ thuộc tầm xa:
Điều này đề cập đến thách thức mà các mô hình n-gram gặp phải trong việc nhận biết mối quan hệ giữa các từ cách xa nhau trong câu hoặc văn bản. Ví dụ: mối liên hệ giữa chủ ngữ của một câu và một động từ xuất hiện muộn hơn nhiều có thể không được n-gram nắm bắt một cách hiệu quả, đặc biệt nếu có nhiều từ xen vào.
Vấn đề thưa thớt với n-gram bậc cao:
Khi chữ ‘n’ trong n-gram tăng lên (chuyển từ bigram sang trigram và hơn thế nữa), số lượng n-gram có thể có sẽ tăng theo cấp số nhân. Nhiều n-gram bậc cao hơn này sẽ không xuất hiện ngay cả trong các tập dữ liệu huấn luyện lớn, dẫn đến vấn đề thưa thớt khi có thể có nhiều n-gram nhưng không đủ dữ liệu để ước tính chính xác xác suất của chúng. Điều này dẫn đến nhiều n-gram có xác suất bằng 0, điều này có thể cản trở hiệu suất của mô hình.
Hết Bài 1-Chương 2
Để đọc hết Series, vui lòng xem lại Khóa học Vỡ Lòng: Mô hình ngôn ngữ lớn (LLM)
