
Các thành phần của LLM
Tìm hiểu về hoạt động bên trong của LLM.

Tổng quan
Hầu hết các LLM đáng chú ý trong những năm gần đây đều được xây dựng trên kiến trúc Transformer. Trước đây, hầu hết các mô hình ngôn ngữ đều dựa vào mạng nơ-ron tích chập hoặc hồi quy, nhưng sự ra đời của các mô hình Transformer đã cách mạng hóa hiệu suất của mô hình ngôn ngữ. Điểm mạnh cốt lõi của các mẫu Transformer là khả năng xử lý văn bản song song, tăng hiệu quả cho các tác vụ ngôn ngữ. Bài học này tìm hiểu sự phức tạp của kiến trúc Transformer, đi sâu vào hai thành phần chính của nó: cơ chế chú ý và cấu trúc bộ mã hóa-giải mã (attention mechanisms and the encoder-decoder structure). Tìm hiểu về các yếu tố này sẽ cho phép chúng ta hiểu rõ hơn về cách các LLM hiện đại như Transformer được huấn luyện (generative pre-trained transformers - GPT) hoạt động và vượt trội trong các nhiệm vụ ngôn ngữ.
Cấu trúc của Transformer
Transformers có thể xử lý đồng thời các phần khác nhau của văn bản đầu vào, giúp cải thiện khả năng hiểu của mô hình về ngữ cảnh của văn bản đầu vào. Trọng tâm của Transformer là hai nguyên tắc cơ bản: sử dụng cơ chế tự chú ý và cấu trúc bộ mã hóa-giải mã. Chúng ta hãy xem xét chi tiết cả hai thành phần chính này dưới đây.
Cơ chế chú ý (Attention Mechanism)
Để hiểu sự cần thiết của cơ chế chú ý, trước tiên chúng ta hãy thảo luận về phần nhúng. Việc nhúng câu hoặc từ (Sentence/word embeddings) liên kết các từ với vectơ sao cho các từ tương tự có vectơ tương tự. Tuy nhiên, một vấn đề rõ ràng với quá trình này là cùng một từ có thể có nghĩa khác nhau trong các ngữ cảnh khác nhau. Ví dụ: một phút có thể đề cập đến một đơn vị thời gian và cũng có thể đề cập đến một cái gì đó nhỏ (Footnote 1). Cơ chế chú ý có thể giúp giải quyết vấn đề này vì chúng cho phép mô hình tập trung vào chỉ một số phần cụ thể của văn bản đầu vào, điều này rất quan trọng để hiểu ngữ cảnh của bất kỳ tác vụ ngôn ngữ nào.
Về cơ bản, sự chú ý cho phép mô hình gán mức độ quan trọng khác nhau cho các phần khác nhau của dữ liệu đầu vào. Ví dụ: khi xử lý một câu, mô hình có thể chú ý hơn đến các từ khóa quan trọng để hiểu ý nghĩa tổng thể của câu.
Tự chú ý (Self-attention) là một loại cơ chế chú ý cho phép mỗi phần của chuỗi đầu vào có thể tương tác và chịu ảnh hưởng của các phần khác. Khi xử lý văn bản, cơ chế tự chú ý trong mô hình Transformer cho phép nó phân tích toàn bộ chuỗi từ một cách đồng nhất.

Ví dụ: trong câu “đồng hồ còn 1 phút”, việc Tự Chú Ý sẽ giúp mô hình quyết định rằng “phút” đề cập đến một đơn vị thời gian trong ngữ cảnh này. Sự hiểu biết này được thực hiện thông qua các tính toán liên quan đến truy vấn, khóa và giá trị. Mỗi từ trong câu được chuyển thành các phần tử này bằng cách sử dụng các trọng số đã học, cho phép mô hình đánh giá mức độ liên quan hoặc mức độ chú ý của từng từ so với các từ khác trong câu. Bằng cách này, mô hình hiểu rằng trong câu cụ thể này, “phút” được liên kết với các khái niệm về thời gian và mức độ khẩn cấp, được biểu thị bằng “còn 1 phút” và “trên đồng hồ”, cung cấp khả năng hiểu văn bản đầu vào theo ngữ cảnh.
Trong Foot note 1 thì câu nói Give me a minute thì ngược lại, bằng việc Tự Chú Ý, mô hình liên kết khái niệm “cho tôi” (Give) và vị ngữ “tôi”, cung cấp khả năng hiểu văn bản theo ngữ cảnh khác.
Bộ mã hóa-giải mã (Encoder-Decoder)
Cấu trúc bộ mã hóa-giải mã là thành phần nền tảng của kiến trúc Transformer, đóng vai trò quan trọng trong cách các mô hình này xử lý và tạo ra ngôn ngữ. Cấu trúc thành phần kép này cho phép mô hình xử lý văn bản đầu vào thành đầu ra có ý nghĩa một cách hiệu quả, điều này rất cần thiết cho nhiều tác vụ ngôn ngữ, từ dịch thuật đến tạo văn bản.
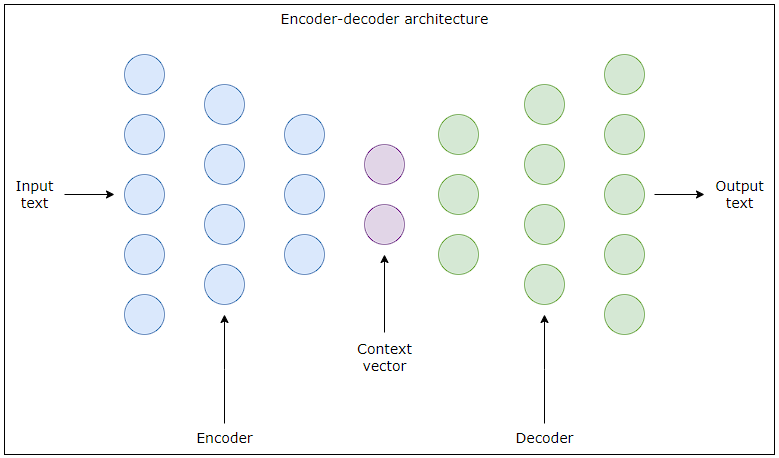
Sơ đồ trên mô tả mạng nơ-ron mã hóa-giải mã để tạo văn bản. Các vòng tròn màu xanh lam ở bên trái đại diện cho các nơ-ron trong mạng lưới thần kinh của bộ mã hóa, mạng này phân tích tuần tự văn bản đầu vào, tinh chỉnh nó thành một vectơ ngữ cảnh (context vector), được biểu thị bằng các vòng tròn màu tím ở giữa. Vectơ này, đầu ra của bộ mã hóa, là sự thể hiện cô đọng ý nghĩa của đầu vào và được đưa vào bộ giải mã để xử lý tiếp. Các vòng tròn màu xanh lá cây ở bên phải minh họa bộ giải mã, bộ giải mã này tái tạo lại văn bản mạch lạc từ vectơ ngữ cảnh, tạo ra phiên bản đã chuyển đổi của đầu vào ban đầu, chẳng hạn như bản dịch hoặc phần tiếp theo. Chúng ta hãy xem xét chi tiết hơn về bộ mã hóa và bộ giải mã bên dưới.
Bộ Mã hoá (Encoder)
Bộ mã hóa xử lý văn bản đầu vào để hiểu ngữ cảnh và sắc thái của nó. Nó biến đổi chuỗi đầu vào thành một chuỗi vectơ, mỗi vectơ đại diện cho các phần khác nhau của đầu vào. Bộ mã hóa có nhiều lớp, trong đó mỗi lớp bao gồm hai thành phần phụ chính: lớp tự chú ý (self-attention layer) và mạng nơ-ron chuyển tiếp nguồn cấp dữ liệu (feed-forward neural network). Lớp tự chú ý sử dụng mọi từ trong chuỗi đầu vào để liên hệ và thông báo cách giải thích cho mọi từ khác. Theo đó, mạng nơ ron chuyển tiếp nguồn cấp dữ liệu xử lý đầu ra từ lớp chú ý bằng cách áp dụng các phép biến đổi tuyến tính và kích hoạt phi tuyến tính để nắm bắt các mẫu cơ bản trong dữ liệu. Khi văn bản đầu vào đi qua các lớp này, nó sẽ biến đổi, dần dần trở nên trừu tượng hơn và phong phú hơn về ngữ cảnh. Văn bản đã xử lý này (được gọi là vectơ ngữ cảnh - context vector) được chuyển đến bộ giải mã cho giai đoạn tạo văn bản tiếp theo thông qua Transformer.
Bộ Giải mã (Decoder)
Bộ giải mã dịch thông tin giàu ngữ cảnh do bộ mã hóa cung cấp thành văn bản đầu ra mạch lạc và có ý nghĩa. Ngược lại với cấu trúc của bộ mã hóa, bộ giải mã bao gồm một số lớp, chẳng hạn như lớp tự chú ý được che giấu (masked self-attention layer), lớp chú ý của bộ mã hóa (encoder attention layer) và mạng thần kinh chuyển tiếp nguồn cấp dữ liệu. Lớp tự chú ý được che giấu đảm bảo bộ giải mã chỉ tập trung vào các từ trước đó (trong một tầm xa đủ gần và vừa mới, ví dụ trong 1 đến 2 câu gần nhất chứ không lấy các từ có trước đó nhưng ở chương trước, quyển trước), duy trì trình tự cần thiết để dự đoán chính xác trong quá trình tạo văn bản. Việc che giấu này ngăn bộ giải mã nhìn thấy các phần trong tương lai của chuỗi, bắt chước quá trình hiểu ngôn ngữ tự nhiên của con người, trong đó mỗi cụm từ được diễn giải trong ngữ cảnh của những gì đã được nói mà không cần biết trước các từ trong tương lai. (Foot note 2)
Trong khi đó, lớp chú ý của bộ mã hóa giúp tích hợp ngữ cảnh do bộ mã hóa cung cấp bằng cách cho phép bộ giải mã tập trung vào các phần có liên quan của chuỗi đầu vào khi nó tạo ra từng từ của đầu ra. Điều này giúp tạo ra kết quả đầu ra phù hợp về mặt ngữ cảnh với đầu vào.
Thành phần cuối cùng, mạng nơ ron chuyển tiếp nguồn cấp dữ liệu, hoạt động tương tự như thành phần trong bộ mã hóa, tinh chỉnh thêm từng từ do bộ giải mã tạo ra bằng cách áp dụng cả phép biến đổi tuyến tính và phi tuyến tính.
Kết hợp lại, các lớp và thành phần này hoạt động cùng nhau trong kiến trúc Transformer để tạo ra các đầu ra nhận biết theo ngữ cảnh cho văn bản đầu vào.
[Foot note]
Trong tiếng Anh có câu nói: Give me a minute thì “a minute” để chỉ tính từ một khoảng thời gian ngắn chứ không có nghĩa đen chính xác một phút như là một đơn vị đo thời gian. Trong tiếng Việt gọi hiện tượng này là đồng âm khác nghĩa, 2 từ đồng âm khác nghĩa sẽ dẫn đến có cùng vectơ (xem lại phần Cơ chế chú ý (Attention Mechanism)). Từ đồng âm khác nghĩa là một loại nhiễu, nhiều này được khử bởi cơ chế Tự Chú Ý- Self Attention Machanism.
Mời bạn đọc thêm về Nắm bắt phụ thuộc tầm xa
Hết Bài 2-Chương 2
Để đọc hết Series, vui lòng xem lại Khóa học Vỡ Lòng: Mô hình ngôn ngữ lớn (LLM)